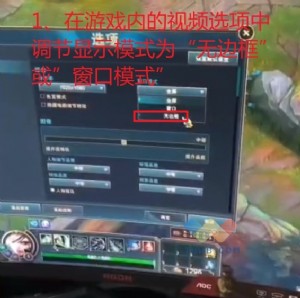
Ш§ВувдЬЋЭјНЛЛЛЛњCPUЪеЗЂАќЮЪЬтЕФЗжЮі
(1)дШЫйЩЯБЈCPU
Ъ§ОнАќдШЫйЩЯБЈCPUЪБЃЌЖдCPUЖгСаЕФГхЛїНЯаЁЃЌЖјЧвЖдCPUЖгСаЕФЛКГхФмСІвЊЧѓВЛИпЃЌCPUЖгСаВЛБизіЕУКмДѓЁЃ
[1] [2] [3] ЯТвЛвГ
(2)ЭЛЗЂ(Burst)ЗНЪНЩЯБЈCPU
НЛЛЛаОЦЌ(ВЩгУASIC)вЛВрЕФгВМўНгЪеЖгСаКЭDMAФкДцПеМфжаЕФЛЗаЮЖгСаЃЌвЛЦ№ИГгшСЫНЛЛЛЛњвЛЖЈЕФЛКГхФмСІ(еыЖдЩЯЫЭCPUЕФЪ§ОнАќ)ЁЃРћгУетИіЛКГхФмСІЃЌЮвУЧПЩвдАбПижЦжмЦкЪЪЕБЗХГЄЃЌВЂЩшЖЈПижЦЕФСЃЖШ(ЕЅЮЛПижЦжмЦкФкCPUЪеБЈИіЪ§ЕФЩЯЯо)ЃЌВЩгУРрЫЦгкЕчТЗжаИКЗДРЁЕФЛњжЦЖЏЬЌЕиЪЙФмКЭЙиБеCPUЪеАќЙІФмЁЃетбљОЭдкКъЙлЩЯЪЕЯжСЫЖдЪ§ОнАќЩЯЫЭCPUЫйТЪЕФПижЦЁЃСэЭтЃЌШчЙћНЛЛЛаОЦЌ(ВЩгУASIC)жЇГжЛљгкСюХЦЭАЫуЗЈЕФCPUЖЫПкГіЗНЯђСїСПМрЙмЛђећаЮЙІФм[2-3]ЃЌЧвМрЙмЛђећаЮЕФзюаЁуажЕПЩвдТњзуCPUЯоЫйЕФашвЊЃЌдђПЩвдРћгУетИіЙІФмПижЦЪ§ОнАќЩЯЫЭCPUЕФНкзрЃЌМѕаЁCPUЕФИКдиЁЃетбљШэМўЕФДІРэОЭМђЛЏСЫКмЖрЁЃ
1.2 CPUЖЫПкЖгСаЕФГЄЖШЙцЛЎ
ШчЙћНіПМТЧНЛЛЛЛњCPUЖЫПкЕФЛКГхФмСІЃЌCPUЖЫПкЖгСаЕБШЛЪЧдНГЄдНКУЃЌЕЋЪЧБиаыМцЙЫЖдЦфЫћЙІФмвдМАадФмЕФгАЯьЁЃеыЖдВЛЭЌЕФASICаОЦЌЃЌашвЊОпЬхЮЪЬтОпЬхЗжЮіЁЃ
1.3 СуПНБД
СуПНБДЪЧжИдкећИіЪ§ОнАќЕФДІРэЙ§ГЬжаЃЌЪЙгУжИеызіВЮЪ§ЃЌВЛНјааећИіЪ§ОнАќЕФПНБДЁЃетбљПЩвдДѓДѓЬсИпCPUЕФДІРэаЇТЪЁЃ
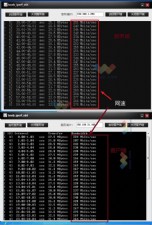
ЪЙгУСуПНБДКѓЃЌЛсвЛЖЈГЬЖШЩЯНЕЕЭШэМўДІРэЕФСщЛюадЃЌЮвУЧЛсУцСйЕНетбљЕФЮЪЬтЃКШчЙћавщеЛашвЊИќИФвЛИіЪ§ОнАќЕФФкШнЃЌЛсжБНгдкНгЪеЛКДц(buffer)ЩЯаоИФЃЌЕЋЪЧШчЙћашвЊдкЪ§ОнАќжаЩОГ§ЛђЬэМгзжЖЮ(Р§ШчЬэМгЛђЩОГ§вЛВуБъЧЉ(tag))ЃЌМДЪ§ОнАќЕФГЄЖШашвЊБфЛЏЪБЃЌгІИУШчКЮДІРэЁЃ
ЬэМгЛђЩОГ§зжЖЮЃЌБиШЛЛсЕМжТЪ§ОнАќЭЗвЛВрЛђАќЮВвЛВрЕФЮЛжУЗЂЩњвЦЖЏЃЌШчЙћАќЮВвЛВрвЦЖЏЃЌЮЪЬтБШНЯМђЕЅЃЌжЛвЊЪ§ОнАќзмГЄЖШВЛГЌЙ§bufferБпНчМДПЩЁЃгЩгкЭЈГЃДЫРрВйзїЖМППНќАќЭЗЕФЮЛжУЃЌШчЙћАќЭЗвЛВрвЦЖЏЃЌаЇТЪЛсБШНЯИпЃЌЫљвдавщеЛдкДІРэЪБПЩФмИќЧуЯђгкдкАќЭЗвЛВрвЦЖЏЃЌетЪБОЭашвЊЧ§ЖЏдкЗжХфbufferЪБзівЛаЉДІРэЃК
(1)НгЪеЪ§ОнАќЪБЃЌЭЗжИеыВЛФмжИЯђbufferБпНчЃЌашвЊЯђКѓЦЋвЦвЛЖЈдЃСПЃЌЭЌЪБЕЅИіbufferЕФДѓаЁвВБиаыМцЙЫЕНзюДѓДЋЫЭЕЅдЊ(MTU)КЭИУдЃСПЁЃ
(2)ЪЭЗХЪ§ОнАќЪБbufferЪзжИеыашвЊзїЙщвЛЛЏДІРэ(ШчЭМ2ЫљЪО)ЁЃ




 ЬьЯТЭјАЩЁЄЭјАЩЬьЯТ
ЬьЯТЭјАЩЁЄЭјАЩЬьЯТ